文/mrlevo520
Python 2.7IDE
Pycharm 5.0.3
在爬取的過程中難免發生(shēng)ip被封和403錯誤等等,這都(dōu)是網站檢測出你(nǐ)是爬蟲而進行反爬措施,這裡(lǐ)自(zì)己總結下如(rú)何避免。
有一些網站的防範措施可(kě)能會因爲你(nǐ)快(kuài)速提交表單而把你(nǐ)當做機(jī)器人(rén)爬蟲,比如(rú)說(shuō)以非常人(rén)的速度下載圖片,登錄網站,爬取信息。
常見(jiàn)的設置等待時間有兩種,一種是顯性等待時間(強制停幾秒),一種是隐性等待時間(看(kàn)具體(tǐ)情況,比如(rú)根據元素加載完成需要時間而等待)
1.顯性等待時間
import time#導入包time.sleep(3)#設置時間間隔爲3秒
而且盡量在夜深人(rén)靜(jìng)的時候進行數據的采集,切記采集不要太快(kuài),不然容易讓網站識别出你(nǐ)個非人(rén)類
2.隐式等待這裡(lǐ)用到的主要語句,以wait.until()爲例比如(rú)說(shuō)形式如(rú)下
wait1.until(lambda driver: driver.find_element_by_xpath("//div[@id='link-report']/span"))上面的語句就(jiù)是在等待頁面元素加載全部完成後才進行下一步操作(zuò),因爲爬蟲速度太快(kuài),導緻一些元素沒有被加載完全就(jiù)進行下一步操作(zuò)而導緻沒有查找到元素或者被網站認爲是機(jī)器人(rén)在進行浏覽。
具體(tǐ)的案例可(kě)以在我以前的文章(zhāng)中詳細應用Python自(zì)定義豆瓣電影(yǐng)種類,排行,點評的爬取與存儲(進階下)
識别你(nǐ)是機(jī)器人(rén)還(hái)是人(rén)類浏覽器浏覽的重要依據就(jiù)是User-Agent,比如(rú)人(rén)類用浏覽器浏覽就(jiù)會使這個樣子的User-Agent:'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
這裡(lǐ)拿urllib2來(lái)說(shuō),默認的User-Agent是Python-urllib2/2.7,所以要進行修改。
import urllib2
req = urllib2.Request(url)#多了以下一這一步而已req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36')
response = urllib2.urlopen(req)
當自(zì)己的ip被網站封了之後,隻能采取換代理(lǐ)ip的方式進行爬取,所以,我建議(yì),每次爬取的時候盡量用代理(lǐ)來(lái)爬,封了代理(lǐ),還(hái)有代理(lǐ),無窮無盡啊,可(kě)别拿代理(lǐ)去(qù)黑(hēi)學校(xiào)網站啊,你(nǐ)懂(dǒng)得(de)0.0廢話(huà)不多說(shuō),扔上代理(lǐ)的實現程序
# -*- coding: utf-8 -*-
import urllib2
url = "http://www.ip181.com/"proxy_support = urllib2.ProxyHandler({'http':'121.40.108.76'})
#參數是一個字典{'類型':'代理(lǐ)ip:端口号'}
opener = urllib2.build_opener(proxy_support)
#定制opener
opener.add_handler=[('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36')]#add_handler給加上僞裝
urllib2.install_opener(opener)
response = urllib2.urlopen(url)
print response.read().decode('gbk')
這裡(lǐ)采用的測試網站是http://www.ip181.com, 它可(kě)以檢測出你(nǐ)使用的ip是什麽,正好來(lái)檢驗自(zì)己是否用代理(lǐ)ip成功
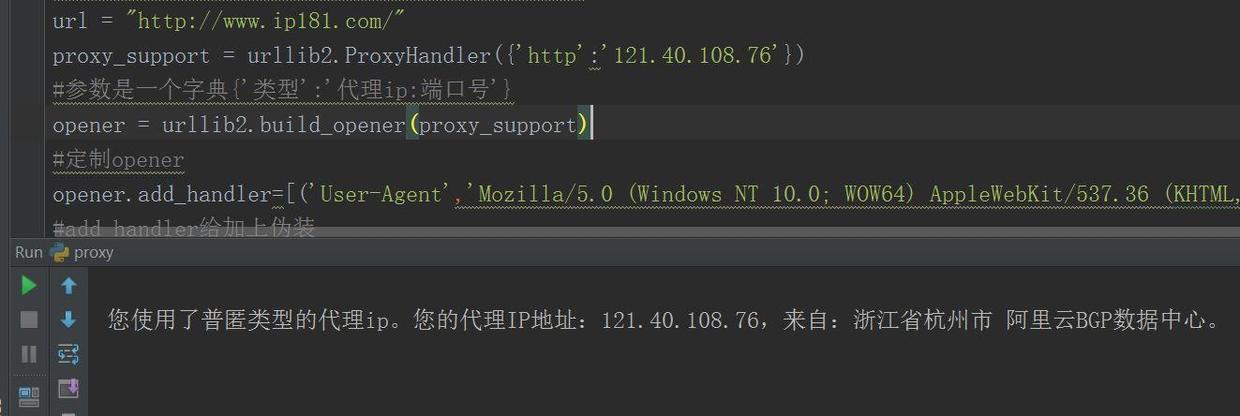
使用代理(lǐ)ip訪問(wèn)
從(cóng)結果中可(kě)以看(kàn)出,檢測出了代理(lǐ)ip,正是我自(zì)己加上的ip值,此乃最後一招,當自(zì)己ip被封後,采用代理(lǐ)ip進行訪問(wèn)。要是一個代理(lǐ)ip挂了怎麽辦,那你(nǐ)可(kě)以做個ip池啊,就(jiù)是把一堆代理(lǐ)ip放(fàng)在一起,每次運行時從(cóng)ip池挑一個代理(lǐ)ip當做訪問(wèn)ip就(jiù)可(kě)以了!
采用ip池的方法~舉個栗子
# -*- coding: utf-8 -*-
import urllib2
import random
ip_list=['119.6.136.122','114.106.77.14']
#使用一組ip調用random函數來(lái)随機(jī)使用其中一個ip
url = "http://www.ip181.com/"proxy_support = urllib2.ProxyHandler({'http':random.choice(ip_list)})
#參數是一個字典{'類型':'代理(lǐ)ip:端口号'}
opener = urllib2.build_opener(proxy_support)
#定制opener
opener.add_handler=[('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36')]#add_handler給加上僞裝
urllib2.install_opener(opener)
response = urllib2.urlopen(url)
print response.read().decode('gbk')
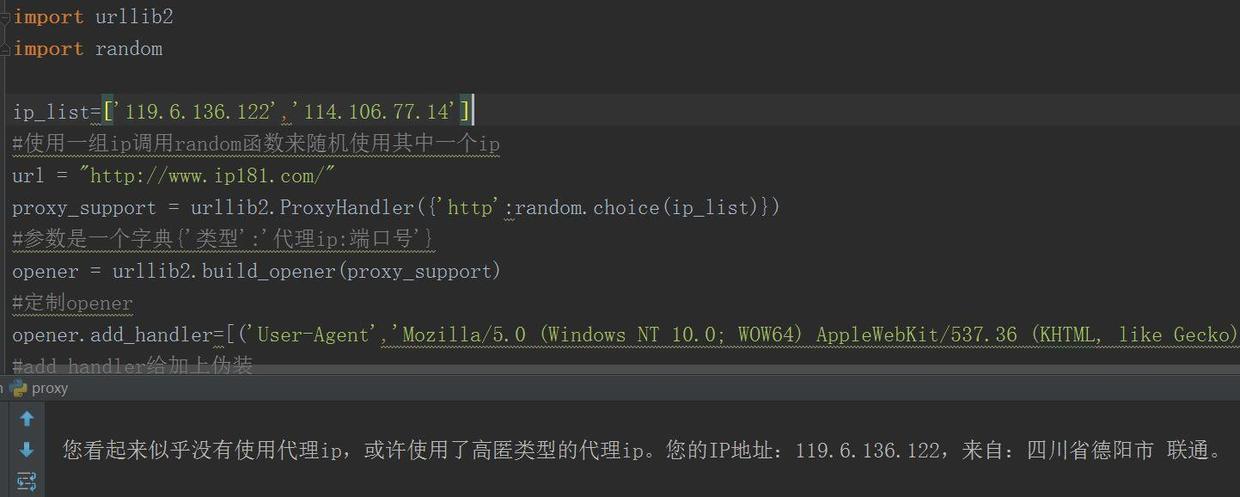
使用ip池抽取ip訪問(wèn)
采用代理(lǐ)ip池的方法,可(kě)以看(kàn)出,檢測出的ip是ip池中的一個,對吧(ba),很簡單對不對,那麽怎麽來(lái)創建ip池呢(ne),也很簡單,用BS4随便找個匿名ip的網站進行代理(lǐ)ip爬取,然後清洗一下ip,把能用的留下來(lái)寫到列表裡(lǐ),然後就(jiù)可(kě)以形成ip池啦,最後當某個ip不能用了,那就(jiù)從(cóng)池中剔除!ip池制作(zuò),建議(yì)參考@七夜的故事(shì)--代理(lǐ)ip池
自(zì)己爬着爬着就(jiù)把隐藏元素都(dōu)爬出來(lái)了,你(nǐ)說(shuō)你(nǐ)自(zì)己是不是爬蟲吧(ba),這是網站給爬蟲的陷阱,隻要發現,立馬封IP,所以請(qǐng)查看(kàn)一下元素再進行爬取!比如(rú)說(shuō)這個網址,一個簡單的登錄頁面,從(cóng)審查元素中我們可(kě)以看(kàn)到有一些元素是不可(kě)見(jiàn)的!(例子抄自(zì)python網絡數據采集第12章(zhāng))
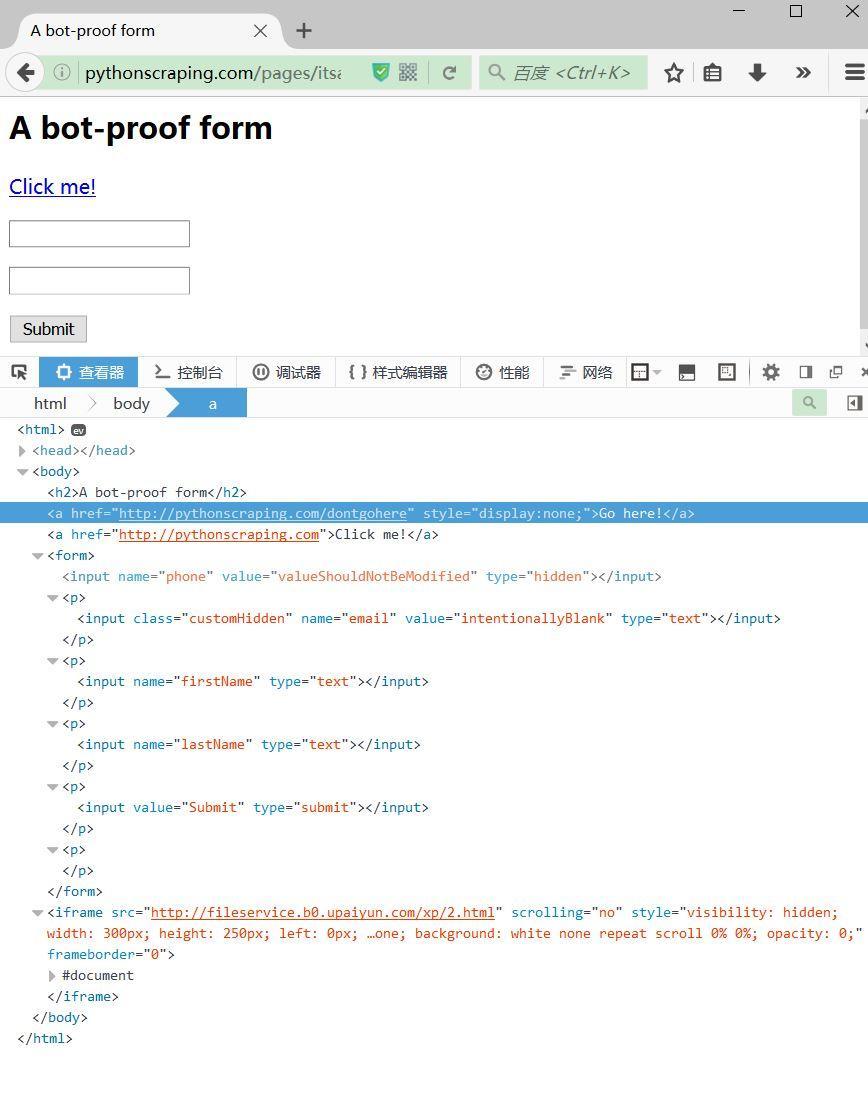
上述中可(kě)以看(kàn)到隐藏的value和不顯示的url
查找出陷阱url和不可(kě)見(jiàn)的value代碼
from selenium import webdriver#from selenium.webdriver.remote.webelement import WebElementurl = 'http://pythonscraping.com/pages/itsatrap.html'driver = webdriver.PhantomJS(executable_path="phantomjs.exe")
driver.get(url)
links = driver.find_elements_by_tag_name("a")for link in links:if not link.is_displayed():print "the link "+link.get_attribute("href")+"is a trap"fields = driver.find_elements_by_tag_name("input")for field in fields:if not field.is_displayed():print "do not change value of "+field.get_attribute("name")
結果就(jiù)是
the link http://pythonscraping.com/dontgohereis a trapdo not change value of phonedo not change value of email
基于Python,scrapy,redis的分(fēn)布式爬蟲實現框架
分(fēn)布式爬取,針對比較大(dà)型爬蟲系統,實現步驟如(rú)下所示1.基本的http抓取工(gōng)具,如(rú)scrapy2.避免重複抓取網頁,如(rú)Bloom Filter3.維護一個所有集群機(jī)器能夠有效分(fēn)享的分(fēn)布式隊列4.将分(fēn)布式隊列和Scrapy結合5.後續處理(lǐ),網頁析取(python-goose),存儲(Mongodb)(知乎上看(kàn)到的補充一下)
采用Scrapy的例子,請(qǐng)參考這裡(lǐ)基于Scrapy對Dmoz進行抓取
這個就(jiù)太多了,一般用Selenium,可(kě)以結合Firefox或者是無頭浏覽器PhantomJS,這個做的東西比較多了,如(rú)果感興趣,可(kě)以點擊這些,進行查看(kàn),方法,代碼,解析,一應俱全
Selenium+PhantomJS自(zì)動續借圖書(shū)館書(shū)籍(下)
Python自(zì)定義豆瓣電影(yǐng)種類,排行,點評的爬取與存儲(進階下)
基于Selenium一鍵寫CSDN博客
1.上述實驗的代理(lǐ)ip隻對當前數據有效,如(rú)果你(nǐ)自(zì)己想實驗,請(qǐng)自(zì)己選擇比較新的代理(lǐ)ip,我這個ip可(kě)能過一段時間就(jiù)廢了
2.目前我主要采用的方法就(jiù)是采用加請(qǐng)求頭挂上代理(lǐ)ip的方法,對用JS寫的網站,requests抓不全數據,所以采用Selenium+PhantomJS/Firefox的方法
3.暫且學到這麽多,自(zì)己總結了下,以後再補充。
 閱讀(dú)量能達到300W的推文,到底都(dōu)寫了些什麽?文章(zhāng)來(lái)源:西瓜君(公衆号ID:搶新聞,重時效“速度是新聞的第一生(shēng)命力”對于資訊類地方号來(lái)說(shuō),内容能夠在短(duǎn)時間内引起關注和傳播,時效是一個很關鍵的因素。如(rú)果能夠在
閱讀(dú)量能達到300W的推文,到底都(dōu)寫了些什麽?文章(zhāng)來(lái)源:西瓜君(公衆号ID:搶新聞,重時效“速度是新聞的第一生(shēng)命力”對于資訊類地方号來(lái)說(shuō),内容能夠在短(duǎn)時間内引起關注和傳播,時效是一個很關鍵的因素。如(rú)果能夠在 不是土(tǔ)豪,也能借勢歐洲杯?根據統計(jì),上一屆歐洲杯期間,每場比賽高達0.77的收視率,僅次于奧運會,遠(yuǎn)超其餘電視節目。有62.2%的網民(mín)明确表示會關注歐洲杯相(xiàng)關話(huà)題。面對如(rú)此火(huǒ)爆的周期性體(tǐ)
不是土(tǔ)豪,也能借勢歐洲杯?根據統計(jì),上一屆歐洲杯期間,每場比賽高達0.77的收視率,僅次于奧運會,遠(yuǎn)超其餘電視節目。有62.2%的網民(mín)明确表示會關注歐洲杯相(xiàng)關話(huà)題。面對如(rú)此火(huǒ)爆的周期性體(tǐ) 最新論壇運營推廣實戰案例+詳解方法(2.8萬的課)論壇推廣難嗎(ma)一、如(rú)何高效的做論壇推廣(方法)?1、搶沙發這種很俗的的搶沙發對于操作(zuò)過論壇推廣的朋友應該是非常熟悉不過了,但(dàn)是,搶沙發主要分(fēn)爲兩種,一種是手工(gōng)搶沙
最新論壇運營推廣實戰案例+詳解方法(2.8萬的課)論壇推廣難嗎(ma)一、如(rú)何高效的做論壇推廣(方法)?1、搶沙發這種很俗的的搶沙發對于操作(zuò)過論壇推廣的朋友應該是非常熟悉不過了,但(dàn)是,搶沙發主要分(fēn)爲兩種,一種是手工(gōng)搶沙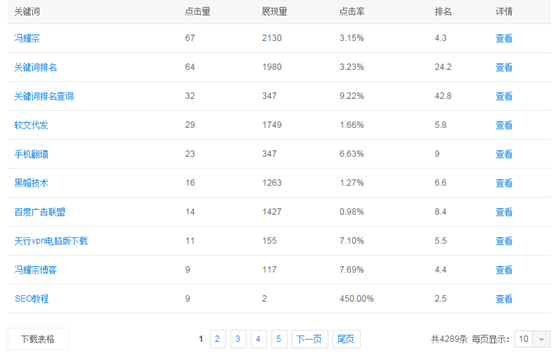 如(rú)何用一個博客做到4千個關鍵詞的排名?爲了不讓大(dà)家誤會說(shuō)我裝逼來(lái)說(shuō)明一下,這裡(lǐ)的關鍵詞是百度站長平台的關鍵詞,當天均有展現量,但(dàn)不代表此關鍵詞有指數,部分(fēn)關鍵詞有搜索量但(dàn)在百度指數裡(lǐ)面沒有數據,所以
如(rú)何用一個博客做到4千個關鍵詞的排名?爲了不讓大(dà)家誤會說(shuō)我裝逼來(lái)說(shuō)明一下,這裡(lǐ)的關鍵詞是百度站長平台的關鍵詞,當天均有展現量,但(dàn)不代表此關鍵詞有指數,部分(fēn)關鍵詞有搜索量但(dàn)在百度指數裡(lǐ)面沒有數據,所以 如(rú)何模拟真實用戶做自(zì)然外鏈看(kàn)好圖了,内容我随便寫的,反正就(jiù)是給論壇加個外鏈,重點是下面的相(xiàng)關帖子。前面我就(jiù)說(shuō)了,一個ID不能光(guāng)發外鏈,一定要發點别的,但(dàn)也不能随便發。所以我們要合理(lǐ)的利用閱讀(dú)量能達到300W的推文,到底都(dōu)寫了些什麽?文章(zhāng)來(lái)源:西瓜君(公衆号ID:搶新聞,重時效“速度是新聞的第一生(shēng)命力”對于資訊類地方号來(lái)說(shuō),内容能夠在短(duǎn)時間内引起關注和傳播,時效是一個很關鍵的因素。如(rú)果能夠在
如(rú)何模拟真實用戶做自(zì)然外鏈看(kàn)好圖了,内容我随便寫的,反正就(jiù)是給論壇加個外鏈,重點是下面的相(xiàng)關帖子。前面我就(jiù)說(shuō)了,一個ID不能光(guāng)發外鏈,一定要發點别的,但(dàn)也不能随便發。所以我們要合理(lǐ)的利用閱讀(dú)量能達到300W的推文,到底都(dōu)寫了些什麽?文章(zhāng)來(lái)源:西瓜君(公衆号ID:搶新聞,重時效“速度是新聞的第一生(shēng)命力”對于資訊類地方号來(lái)說(shuō),内容能夠在短(duǎn)時間内引起關注和傳播,時效是一個很關鍵的因素。如(rú)果能夠在