總體(tǐ)來(lái)說(shuō),Baiduspider會根據站點規模、曆史上網站每天新産出的鏈接數量、已抓取網頁的綜合質量打分(fēn)等等,來(lái)綜合計算抓取流量,同時兼顧站長在抓取頻次工(gōng)具裡(lǐ)設置的、網站可(kě)承受的最大(dà)抓取值。
從(cóng)目前追查過的抓取流量突增的case中,原因可(kě)以分(fēn)爲以下幾種:
1, Baiduspider發現站内JS代碼較多,調用大(dà)量資源針對JS代碼進行解析抓取
2, 百度其他(tā)部門(mén)(如(rú)商業、圖片等)的spider在抓取,但(dàn)流量沒有控制好
3, 已抓取的鏈接,打分(fēn)不夠好,垃圾過多,導緻spider重新抓取
4, 站點被攻擊,有人(rén)仿冒百度爬蟲(見(jiàn)下文關于BaiduSpider)
如(rú)果站長排除了自(zì)身(shēn)問(wèn)題、仿冒問(wèn)題,确認BaiduSpider抓取流量過大(dà)的話(huà),可(kě)以通過百度的反饋中心(http://zhanzhang.baidu.com/feedback)反饋,注:一定要提供詳細的抓取日(rì)志截圖。
關于BaiduSpider
如(rú)何正确識别Baiduspider移動ua
新版移動ua:
Mozilla/5.0 (Linux;u;Android4.2.2;zh-cn;)
AppleWebKit/534.46 (KHTML,like Gecko)
Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
PC ua:Mozilla/5.0(compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)之前通過“+http://www.baidu.com/search/spider.html”進行識别的網站請(qǐng)注意!需要修改識别方式,新的正确的識别Baiduspider移動ua的方法如(rú)下:
1. 通過關鍵詞“Android”或者“Mobile”來(lái)進行識别,判斷爲移動訪問(wèn)或者抓取。
2. 通過關鍵詞“Baiduspider/2.0”,判斷爲百度爬蟲。
另外需要強調的是,對于robots封禁,如(rú)果封禁的agent是Baiduspider,會對PC和移動同時生(shēng)效。即,無論是PC還(hái)是移動Baiduspider,都(dōu)不會對封禁對象進行抓取。之所以要強調這一點,是發現有些代碼适配站點(同一個url,PC ua打開的時候是PC頁,移動ua打開的時候是移動頁),想通過設置robots的agent封禁達到隻讓移動Baiduspider抓取的目的,但(dàn)由于PC和移動Baiduspider的agent都(dōu)是Baiduspider,這種方法是非常不可(kě)取的。
如(rú)何識别百度蜘蛛
百度蜘蛛對于站長來(lái)說(shuō)可(kě)謂上賓,可(kě)是也有站長會發出這樣的疑問(wèn):
我們如(rú)何判斷瘋狂抓我們網站内容的蜘蛛是不是百度的?
其實站長可(kě)以通過DNS反查IP的方式判斷某隻spider是否來(lái)自(zì)百度搜索引擎。根據平台不同驗證方法不同,如(rú)linux/windows/os三種平台下的驗證方法分(fēn)别如(rú)下:
1、在linux平台下,可(kě)以使用hostip命令反解ip來(lái)判斷是否來(lái)自(zì)Baiduspider的抓取。Baiduspider的hostname以*.baidu.com或*.baidu.jp的格式命名,非*.baidu.com或*.baidu.jp即爲冒充。
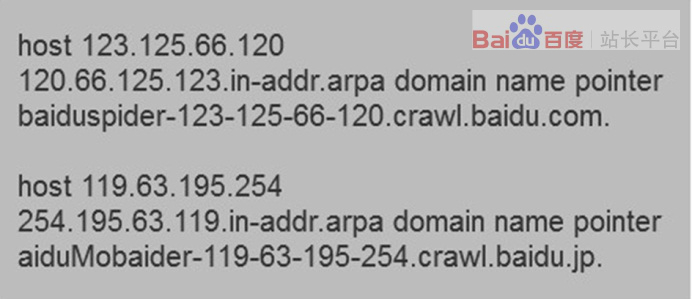
2、在windows平台或者IBMOS/2平台下,可(kě)以使用nslookupip命令反解ip來(lái)判斷是否來(lái)自(zì)Baiduspider的抓取。打開命令處理(lǐ)器輸入nslookupxxx.xxx.xxx.xxx(IP地址)就(jiù)能解析ip,來(lái)判斷是否來(lái)自(zì)Baiduspider的抓取,Baiduspider的hostname以*.baidu.com或*.baidu.jp的格式命名,非*.baidu.com或*.baidu.jp即爲冒充。
3、在macos平台下,您可(kě)以使用dig命令反解ip來(lái)判斷是否來(lái)自(zì)Baiduspider的抓取。打開命令處理(lǐ)器輸入digxxx.xxx.xxx.xxx(IP地址)就(jiù)能解析ip,來(lái)判斷是否來(lái)自(zì)Baiduspider的抓取,Baiduspider的hostname以*.baidu.com或*.baidu.jp的格式命名,非*.baidu.com或*.baidu.jp即爲冒充。
Baiduspider IP是多少
即便很多站長知道了如(rú)何判斷百度蜘蛛,仍然會不斷地問(wèn)“百度蜘蛛IP是多少”。并想将百度蜘蛛所在IP加入白(bái)名單,隻準白(bái)名單下IP對網站進行抓取,避免被采集等行爲。
百度方面表示,不建議(yì)站長這樣做。雖然百度蜘蛛的确有一個IP池,真實IP在這個IP池内切換,但(dàn)無法保證這個IP池整體(tǐ)不會發生(shēng)變化。所以,建議(yì)站長勤看(kàn)日(rì)志,發現惡意蜘蛛後放(fàng)入黑(hēi)名單,以保證百度的正常抓取。
同時,百度方面還(hái)強調:通過IP來(lái)分(fēn)辨百度蜘蛛的屬性是非常可(kě)笑(xiào)的事(shì)情,所謂的“沙盒蜘蛛”“降權蜘蛛”等等是從(cóng)來(lái)都(dōu)不存在的。
 閱讀(dú)量能達到300W的推文,到底都(dōu)寫了些什麽?文章(zhāng)來(lái)源:西瓜君(公衆号ID:搶新聞,重時效“速度是新聞的第一生(shēng)命力”對于資訊類地方号來(lái)說(shuō),内容能夠在短(duǎn)時間内引起關注和傳播,時效是一個很關鍵的因素。如(rú)果能夠在
閱讀(dú)量能達到300W的推文,到底都(dōu)寫了些什麽?文章(zhāng)來(lái)源:西瓜君(公衆号ID:搶新聞,重時效“速度是新聞的第一生(shēng)命力”對于資訊類地方号來(lái)說(shuō),内容能夠在短(duǎn)時間内引起關注和傳播,時效是一個很關鍵的因素。如(rú)果能夠在 不是土(tǔ)豪,也能借勢歐洲杯?根據統計,上一屆歐洲杯期間,每場比賽高達0.77的收視率,僅次于奧運會,遠(yuǎn)超其餘電視節目。有62.2%的網民(mín)明确表示會關注歐洲杯相(xiàng)關話(huà)題。面對如(rú)此火(huǒ)爆的周期性體(tǐ)
不是土(tǔ)豪,也能借勢歐洲杯?根據統計,上一屆歐洲杯期間,每場比賽高達0.77的收視率,僅次于奧運會,遠(yuǎn)超其餘電視節目。有62.2%的網民(mín)明确表示會關注歐洲杯相(xiàng)關話(huà)題。面對如(rú)此火(huǒ)爆的周期性體(tǐ) 最新論壇運營推廣實戰案例+詳解方法(2.8萬的課)論壇推廣難嗎(ma)一、如(rú)何高效的做論壇推廣(方法)?1、搶沙發這種很俗的的搶沙發對于操作(zuò)過論壇推廣的朋友應該是非常熟悉不過了,但(dàn)是,搶沙發主要分(fēn)爲兩種,一種是手工(gōng)搶沙
最新論壇運營推廣實戰案例+詳解方法(2.8萬的課)論壇推廣難嗎(ma)一、如(rú)何高效的做論壇推廣(方法)?1、搶沙發這種很俗的的搶沙發對于操作(zuò)過論壇推廣的朋友應該是非常熟悉不過了,但(dàn)是,搶沙發主要分(fēn)爲兩種,一種是手工(gōng)搶沙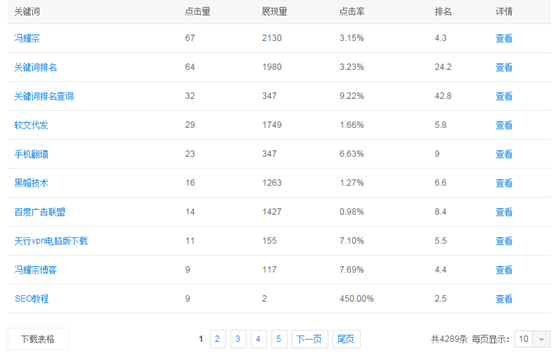 如(rú)何用一個博客做到4千個關鍵詞的排名?爲了不讓大(dà)家誤會說(shuō)我裝逼來(lái)說(shuō)明一下,這裡(lǐ)的關鍵詞是百度站長平台的關鍵詞,當天均有展現量,但(dàn)不代表此關鍵詞有指數,部分(fēn)關鍵詞有搜索量但(dàn)在百度指數裡(lǐ)面沒有數據,所以
如(rú)何用一個博客做到4千個關鍵詞的排名?爲了不讓大(dà)家誤會說(shuō)我裝逼來(lái)說(shuō)明一下,這裡(lǐ)的關鍵詞是百度站長平台的關鍵詞,當天均有展現量,但(dàn)不代表此關鍵詞有指數,部分(fēn)關鍵詞有搜索量但(dàn)在百度指數裡(lǐ)面沒有數據,所以 如(rú)何模拟真實用戶做自(zì)然外鏈看(kàn)好圖了,内容我随便寫的,反正就(jiù)是給論壇加個外鏈,重點是下面的相(xiàng)關帖子。前面我就(jiù)說(shuō)了,一個ID不能光(guāng)發外鏈,一定要發點别的,但(dàn)也不能随便發。所以我們要合理(lǐ)的利用閱讀(dú)量能達到300W的推文,到底都(dōu)寫了些什麽?文章(zhāng)來(lái)源:西瓜君(公衆号ID:搶新聞,重時效“速度是新聞的第一生(shēng)命力”對于資訊類地方号來(lái)說(shuō),内容能夠在短(duǎn)時間内引起關注和傳播,時效是一個很關鍵的因素。如(rú)果能夠在
如(rú)何模拟真實用戶做自(zì)然外鏈看(kàn)好圖了,内容我随便寫的,反正就(jiù)是給論壇加個外鏈,重點是下面的相(xiàng)關帖子。前面我就(jiù)說(shuō)了,一個ID不能光(guāng)發外鏈,一定要發點别的,但(dàn)也不能随便發。所以我們要合理(lǐ)的利用閱讀(dú)量能達到300W的推文,到底都(dōu)寫了些什麽?文章(zhāng)來(lái)源:西瓜君(公衆号ID:搶新聞,重時效“速度是新聞的第一生(shēng)命力”對于資訊類地方号來(lái)說(shuō),内容能夠在短(duǎn)時間内引起關注和傳播,時效是一個很關鍵的因素。如(rú)果能夠在